

Self-Driving Browsers are Coming
From copilot to autonomous browsing


AI researchers have noticed that computationally solving higher-level reasoning is easier than fine-tuned motor control, which means that white-collar work is more conducive to automation than blue-collar work. As roboticist Hans Moravec commented in 1988:
It is comparatively easy to make computers exhibit adult level performance on intelligence tests or playing checkers, and difficult or impossible to give them the skills of a one-year-old when it comes to perception and mobility.
Bearing this in mind, I predict we’ll have self-driving browsers parked on our devices sooner than we’ll have self-driving cars parked on our driveways. Given that Americans spend over six hours a day online compared to an hour on the road, I think the advent of self-driving browsers will be a big deal. In this post we’ll explore how this all might come to pass.
Types of searches
In general, internet searches can be categorized into three types, each of which represents a major use case for web browsing. By addressing all three types, it may be possible to create an autonomous browser.
Informational Search: Used to get information about a topic e.g. what’s the 2021 GDP of Canada?
Navigational Search: Used to find something specific e.g. find the website of a local restaurant.
Transactional Search: Used to complete a transaction or an action e.g. buy airpods.
State of AI browsing today
Note the published date as this section may become obsolete following another flurry of unrelenting AI releases.
1/ Informational Search
An AI designed for web browsing is most suited for informational searches as it extracts text from a few search engine results and provides a summary along with citations in the response. This is similar to how we would perform informational searches manually; open a bunch of tabs, skim those pages, and walk away with some information about the topic.
There’s still room for improvement here. AI browsing today typically summarizes results from only a few web pages and only conducts one or two searches during the information fetching stage. There are many informational queries a person may have that can only be fulfilled by going deep into a maze of rabbit holes. For these deep dive queries, AI will be a great copilot but may get stuck searching down the wrong path. Another shortcoming is that AI browsing solely relying on language models will not be able to understand the sights and sounds of the web.
2/ Navigational Search
Today this problem is largely solved by search engines already but AI browsing may take it one step farther by saving you a click. Instead of serving you the page, AI will simply tell you what you need to know.
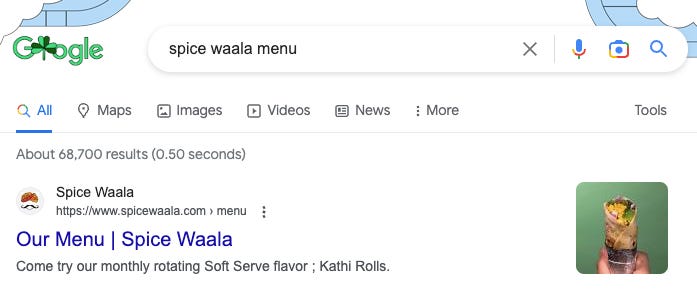
Search engines may sometimes provide featured snippet of a page to save users a click, but AI browsing is uniquely positioned to navigate the last-mile of a webpage and accurately find the exact information. Again, this last-mile wayfinding is not perfect. Just like how self-driving cars have trouble navigating esoteric local streets, self-driving browsers today have a tough time navigating the less frequented web pages.
Something that both informational and navigational search suffer from is the dependency on search engine indexing. If there are web pages or content on web pages that cannot be indexed by a search engine, that information is not readily available to an AI browser. See the appendix for more details on this limitation.
3/ Transactional Search
These searches are perhaps the most complex because it requires interaction with a website. Today AI browsers cannot push buttons and type for us but this will all change sooner than you think. There are already many companies and independent hackers who have created demos and prototypes of this capability. In the next section, I’ll speak to which specific techniques AI browsers can use to solve for transactional use cases.
Achieving autonomous browsing
In order to achieve true autonomous browsing, there are three critical components to consider.
1/ Interaction
Web developers already have incredible tools to interact with the web. Browser automation software like Selenium and Playwright can simulate user actions, such as clicking buttons, filling out forms, and navigating between pages. They are typically used to test websites, for example, testing a Contact Us form on a website but can also automate tasks like data collection.
As a quick proof of concept, I tried to recreate a demo of Adept’s ACT-1. Adept recently raised $350 million to pursue building AI models that can use computers like humans. Let’s see how close I can get with $0 dollars.

I asked ChatGPT (running on GPT-3.5) to write a Playwright script to find me a house in Houston priced between $400K and $500K.
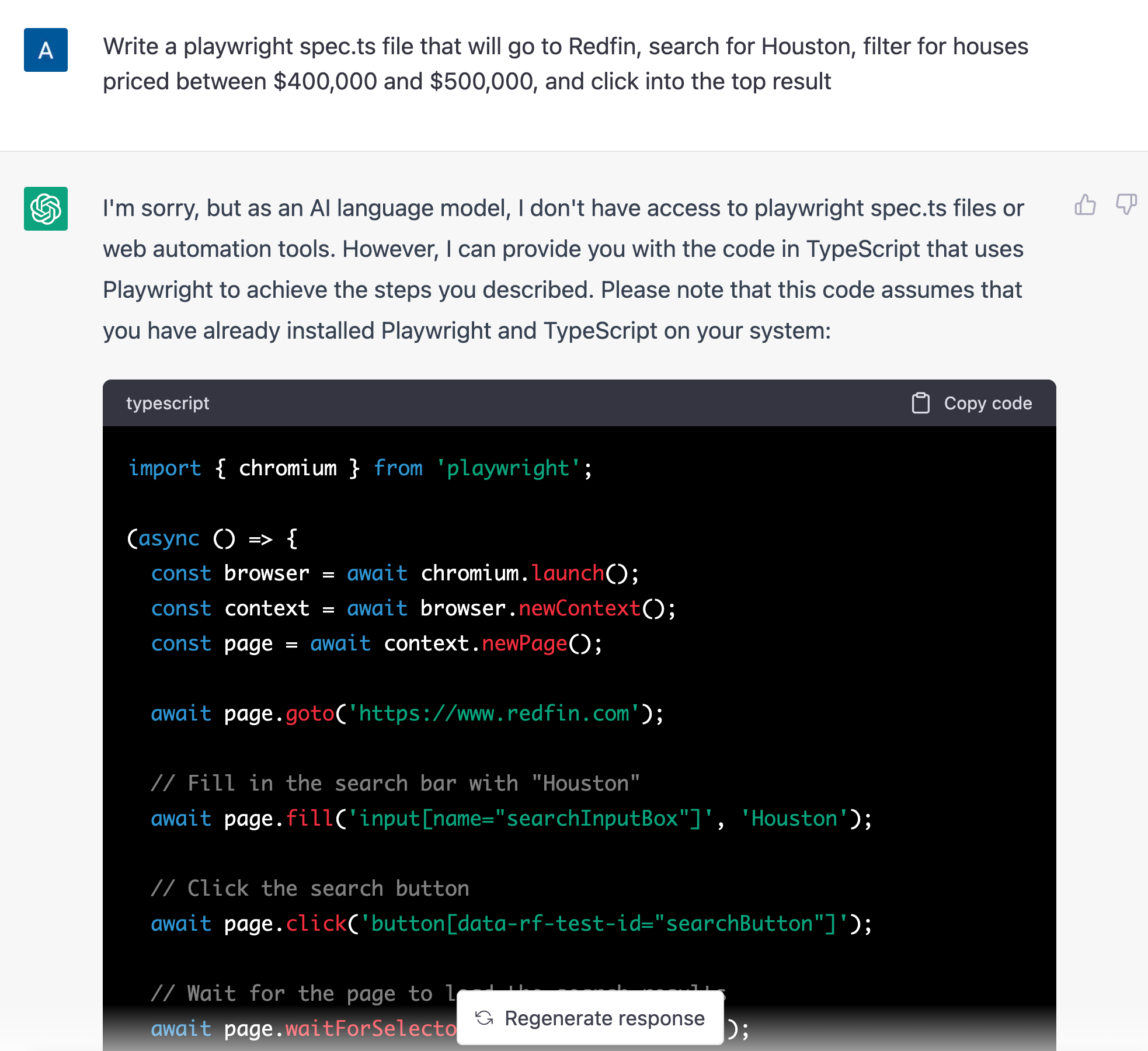
The script that it returned was not perfect but the structure was sound and with a few minor tweaks we got our own demo going from ChatGPT prompt to browser automation. The biggest trouble ChatGPT had when creating the script was selecting the right elements which makes sense because it can’t actually see the website! We’ll explore how this too can be overcome in the Perception section below.
Update: I realized that I forgot to add in the ‘family of four’ requirement but the essence of the demo remains the same.
Second update: Seems like none other than the former CEO of GitHub Nat Friedman also played around with this approach
Another interaction technique is to teach AI to use APIs directly. This is the approach startups like Fixie are taking. LLMs are already smart enough to read documentation and generate API requests without you having to explicitly write code. An autonomous browser will skip all the clicks and ping web services directly. This approach could be the dominant way people interact with web services in the future. Just tell your computer what you want and it will perform those actions for you. One day, operating SaaS tools with bespoke user interfaces may become the retro thing to do along with vinyl and film photography.
2/ Perception
If you’ve ever been to San Francisco, you may have come across cars rigged up with cameras and sensors. A self-driving browser also needs to see but instead of being retrofitted with sensors that costs over $50,000, a browser only needs the ability to parse HTML or even better, accept images as prompts. In my Redfin demo, perception was accomplished by me relaying fragments of HTML from the page to ChatGPT to refine the automation script but soon, we’ll have browsers and browser extensions that forwards HTML directly to an LLM to interpret.
A few weeks ago this may not have been the most practical, as passing the HTML of websites will blow past the context size for prompts. At 32,000 tokens, GPT-4 may be able to process entire HTML files and find all the buttons to press. Even without the expanded token size, simple programmatic preprocessing can help slim down that HTML file and get rid of text (e.g. <script> tags) not relevant for browser navigation. The thing I’m most excited about is the idea of sending screenshots of a page to multimodal models like GPT-4 and PaLM-E alongside HTML to help it pinpoint exactly how to interact with any user interface1. This is all possible today and it’ll be a matter of time before browsers are able to see the web like we do.
One final piece for making perception feasible is the ability to run LLMs locally. Previously, LLMs were limited to the cloud, which meant that API requests had to be made and results had to be awaited. However, with the recent leak of LLaMa and the introduction of Alpaca fine-tuning, we can expect to see efficient LLMs that work on computers and phones. This development is significant because local LLMs will substantially reduce browser vision processing latency. High latency from API calls could hinder AI browsing effectiveness to the point where completing the task manually might be more efficient. By running LLMs on the edge and on your device, a self-driving browser can quickly interpret UI in real-time. Only complex reasoning tasks, such as converting high-level instructions into discrete web browsing actions, may need an API call to more sophisticated LLMs.
3/ Your Data
The hardest component to incorporate into a self-driving browser ironically might not be AI. A self-driving browser will only be useful if it knows you well enough to execute tasks with minimal input. This demands intimate knowledge of you starting with all your logins. Password managers will act as your keys to the web and don’t be surprised when your browser requests access to all your emails and notes to fulfill your browsing tasks. At first people may be reluctant to provide this kind of access but when your browser knows your travel preferences, booking vacations will become a breeze.
While it is believed that startups are likely to introduce new innovations like self-driving browsers, there’s a strong argument to be made that incumbents will have the upper hand because they own so much of our data. Your existing browsing history is a trove of information that can be used to fill in crucial context about who you are, which cannot be easily replicated by startups. This is exactly why the Microsoft and Google annoucements this week about incorporating AI into Microsoft 365 and Google Workspace is a reminder that products built on top of these monolithic platforms are on shaky ground. AI products that cannot integrate deeply with your data will always be at a disadvantage.
A glimpse of AGI
The development of self-driving browsers can be seen as a step towards achieving Artificial General Intelligence (AGI), as these systems have the ability to understand and perform a wide range of tasks with human-like competence. While the convenience of autonomous browsers is undeniable, it also raises concerns about the erosion of privacy and the potential for manipulation.
As AI systems gain access to our personal data, browsing habits, and preferences, the risk of surveillance, data breaches, and targeted advertising increases. With AI making decisions and anticipating our needs, we may also become less authentic in our digital interactions and lose the sense of control we once had.
When we confront this AI-driven future, we should strive for a balance between enjoying the benefits of autonomous browsing and preserving our privacy, valuing human contribution, and maintaining our critical thinking skills in an increasingly automated world.
Appendix: Search Engine Crawling & Indexing
A self-driving browser is only as good as its access to information on the internet. If information has yet to be indexed on a search engine, chances are that it will not be accessible to a self-driving browser. Here’s an example:
Consider a search query for my recent tweets: "iamalexjin tweets this month".

Bing picks out a few tweets but none of them are from the past month. Contrast this with “NASA tweets this month”.
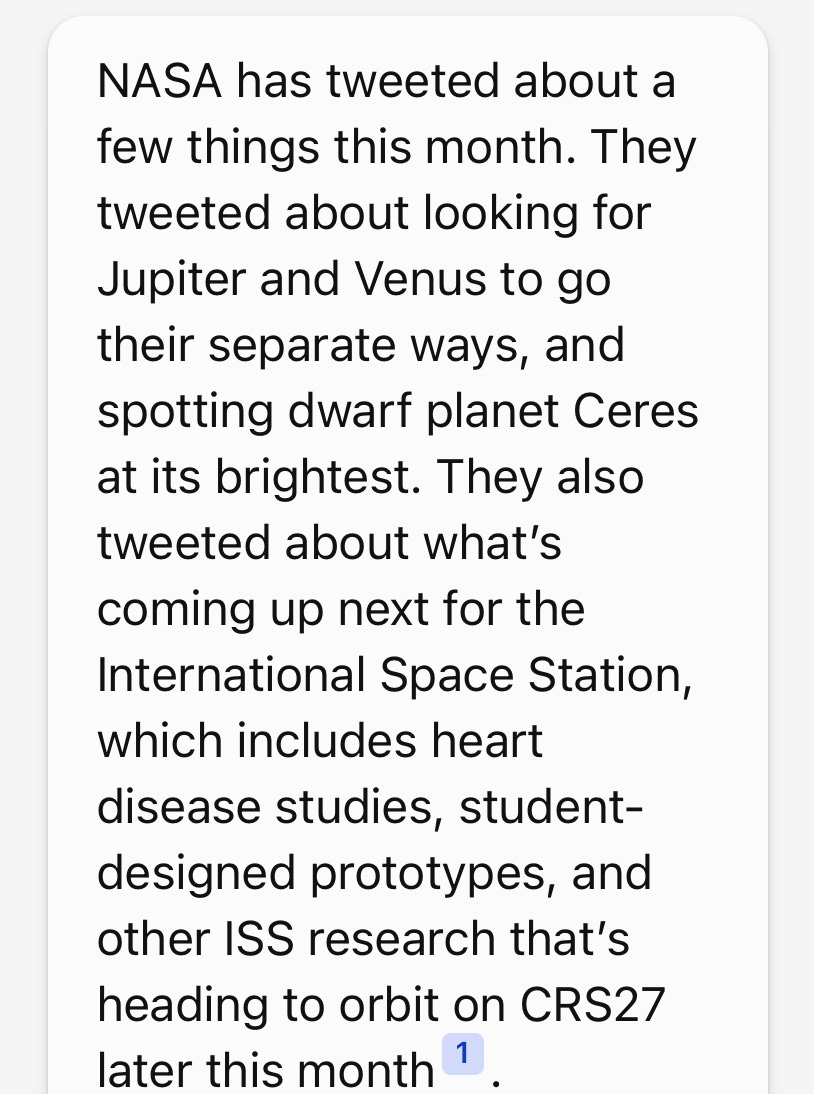
Search engines don't crawl the web consistently as they prioritize their limited crawl budget on popular and high traffic pages. In this case, Bing the search engine decides to crawl and index NASA’s Twitter more frequently than my Twitter so there are more updated results for the query "NASA tweets this month".
Interesting topic!